机器学习|Ryzen再一次被碾压,英特尔12代酷睿为什么这么强?

文章图片

文章图片
文/小编
自从Ryzen系列崛起之后 , 英特尔的日子越来越不好过了 , 虽然在最终的市场份额上 , 英特尔依旧是吊锤AMD , 但是在具体的市场表现上 , AMD的Ryzen处理器已经越来越受欢迎 。 甚至就连移动端平台 , AMD处理器的表现都相当抢眼 。 至于一些DIY爱好者更是把物美价廉的Ryzen处理器当作是心头好 , 同时也涌现了一大堆“死忠粉” , AMD YES的口号也是不绝于耳 。
而反观英特尔这边 , 由于在制造工艺方面的桎梏 , 其TICK-TOCK战略一直无法顺利的进行下去(TICK是工艺 , TOCK是架构) , 因为架构的升级一般都要以工艺的升级作为基础 。
而这就导致了英特尔在架构升级方面一直进展缓慢 , 从酷睿6代开始的Skylake架构 , 缝缝补补用了五年多 , 一直从酷睿六代用到了十代 。
到了11代酷睿芯片上 , 英特尔终于换装了全新的架构——Cypress Cove , 不过这个架构所带来的提升比较有限 , 是一个带有过渡性质的架构 , 不过 , 就是这个架构就已经让英特尔基本追平了AMD的Zen3架构 。
这里面其实也要说一点 , 英特尔的14nm架构 , 听起来很落后 , 但是单论单位面积的晶体管密度是要比台积电、三星等IC制造厂所谓10nm架构要高的 , 基本上可以达到8nm的水准 。 因为英特尔在命名的时候其实是比较忠于“物理数据的” , 也就是晶体管栅极的大小 , 而台积电 , 三星更多的只是把\"几纳米\"中的数字当做了一个形容工艺节点的符号 。
而到了12代酷睿这一代 , 英特尔不仅对架构进行了全面的提升 , 并且终于开始对工艺进行全方位的提升 。
12代酷睿所用的工艺名为“lntel 7”的工艺 , 虽然含有数字7 , 但是他其实还是10nm工艺的底子 , 只不过做了相当程度的巨大优化 , 更准确的叫法其实应该是10nm+++工艺 。
大家别看他是10nm工艺 , 但是它的实际晶体管密度已经可以和台积电 , 三星等IC生产企业所标称的7nm工艺相提并论了 。 (从这里也可以看出来 , 英特尔终于开窍了 , 会开始玩命名游戏了)
【机器学习|Ryzen再一次被碾压,英特尔12代酷睿为什么这么强?】紧接着还有架构方面的提升 。
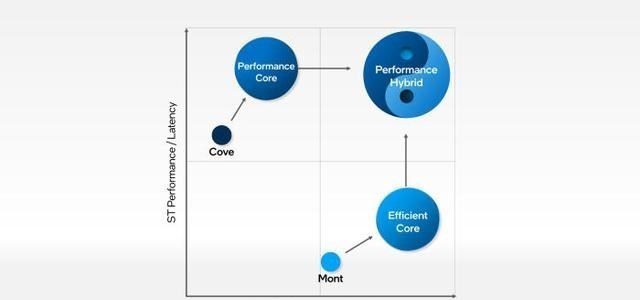
Alder Lake架构最重要的技术升级就来自于“大小核异构”的设计 , 这一点和ARM处理器的架构有一定的相似之处 , 譬如骁龙888CPU部分采用的就是1+3+4的三丛集式设计 , 也就是一颗超大核心+三颗大核心+四枚小核心 。
而Alder Lake架构的模式也是类似的 , 简单来说就是大核心+小核心的大+小的配置 , 大核心负责极限峰值性能输出 , 小核心负责日常轻度输出 , 这样做的好处是可以尽可能地兼顾性能和功耗 , 并且也让芯片在参数上更加好看 。 (如果用16颗大核心 , 功耗太高 , 如果只用8颗大核心 , 参数上又不太好看)
别看这套大小核的架构在ARM处理器上已经有了丰富的应用 , 但是在X86 CPU上还算是首创(英特尔曾经在Lakefield上试水过 , 但是并未大规模商用) 。
此外 , 英特尔还对后端的发射单元 , 缓存等做了大幅度的提升 , 其能效核与Skylake核心相比 , 能效核能够在相同功耗下实现40%的单线程性能提升 。
这一点在目前的跑分中已经得到了体现 , 12代酷睿处理器的单核性能以绝对的碾压态势吊打了AMD Ryzen所有现役的CPU , 优势达到了30%以上 , 这可以说是自从Ryzen处理器发布以来 , 英特尔少有的高光时刻 , 如下图所示 , Intel酷睿i5-12600K在单核性能方面实现了默秒全 。
相关经验推荐












- iphone13|这次iPhone13真带了一个好头,国产机不得已,只能学习
- 机器人|预算紧张补上骁龙8系旗舰,这款2K档新机担值得考虑
- 工业机器人|曾嘲笑苹果的它,最终变成了曾经讨厌的模样,刘海加持
- 机器人|高端制造高歌猛进,中国要在机器人技术领域杀出一条血路!
- 机器人|四轴和六轴机器人的区别是什么,看了就知道!
- 苹果|有颜有值有实力,云米AI扫拖机器人Alpha 3体验:做个懒人,真舒坦
- 英特尔|号称“没有竞品”!百度首款汽车机器人靠谱吗?
- 机器学习|?机器学习和人工智能的应用,在心脏病学的许多领域实现了更快的诊断
- VR|疫情当下,足不出户,家用VR多用机,健身减肥娱乐学习一机多用!
- 机器人|手机内部有自动优化,绿树会更绿,脸色会轻微偏好看的红色