现在人工智能深度学习领域 , 图形图像、机器视觉相关的子领域火得一塌糊涂 。 也难怪 , 类似卷积神经网络、生成式对抗网络这种天生适合于图像处理的AI技术 , 现在被技术人程序员玩出花来了 。 相关的研究突破也时有报道 。
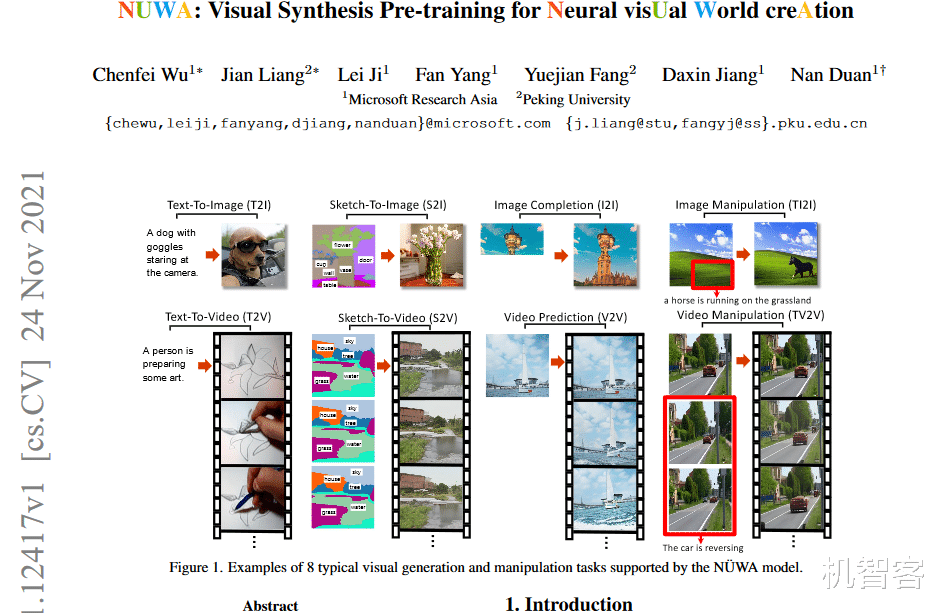
有一个新的论文发表了 。 想必关注人工智能技术圈的朋友都了解一些 。 这项研究是一个新的视觉合成模型:Nüwa(女娲) 。 和之前很火的GauGAN比 , 女娲模型生成方式更加多样化 。 有文本涂鸦 , 有文本生成视频 , 有AI想象补全 , 视频预测多种功能 。 看资讯GitHub上还有已经开源的项目 。 于是机智客跑过去一看 , 原来就一个介绍和几个图片 , 并没有代码和演示类demo 。 论文里介绍得很详细 , 看下论文目录 , 从上往下拖走马观花眼花缭乱 。
【女娲|未来要啥有啥的虚拟假世界,可能都是现在这些AI生成的】从技术上看 , 它提出了一个通用的 3D transformer——编码器-解码器框架 。 涵盖了语言、图像和视频 , 可用于多种视觉合成任务 。 该框架由以文本或视觉草图作为输入的自适应编码器和由8个视觉合成任务共享的解码器组成 。 另外 , 它还包含一种3D Nearby Attention (3DNA)机制 , 以考虑空间和时间上的局部特征 。
通过多项实验评估的合成结果 , 和其他模型相比 , 女娲有明显的优势 。 尽管有的模型性能上比女娲略好一点 , 不过女娲在生成逼真的图像上 , 还是有优势的 。 更多的内容可以参考论文原文 , 反正机智客造的纸(造诣)很薄 , 都没看完整个英文论文原文 。
感觉 , 现在很多这方面的研究 , 都在为我们营造一个AI生成的逼真世界 。 也许吧 , 在未来 , 在那个愈发虚拟的时代 , 也许正如电影里拍摄的 , 要啥有啥 。 我们在虚拟世界体验到的 , 和现实中物理感官感觉的不差什么 。 而彼时 , 则AI会主导大多的渲染和生成任务 。 如果元宇宙是未来必然的发展落地方向 , 机智客个人总觉得我们在虚拟的假世界里体验到的一切 , 或者我们自己想要的东西 , 都会是人工智能给我们生成和合成的 。 毕竟 , 当前这些不断发表的论文、技术实现 , 很多都是图像、视频方面的 。 以后辅以声音、语言乃至以后的触觉等其他感官延伸 , 新时代虚拟世界就齐活了 。
假的东西越来越真 , 缺漏或不存在的东西 , AI越来越会弥补了 , 简直是得心应手 。 当然这些畅想 , 可能会成真 , 也可能会发展到另外的方向 。 拭目以待我们共同的未来吧 。
相关经验推荐












![QQ飞车手游裂地玄甲怎么改?雷诺重工裂地玄甲改装加点攻略[多图]](http://img1.jingyanla.com/220427/050A94H5-0-lp.jpg)

- 显卡|5nm撑不住 RTX 4090/Ti显卡功耗飙升:要上1200W电源
- 小米科技|Intel/AMD/NV等撑不住!CPU、GPU等今年都要大涨价
- 苹果|三款高价低能手机,大家最好还是绕道行,不要上手避免交智商税
- vivo NEX|春节过后要来的8款新机,有的已经正式入网,有的参数也已详细!
- 5G|人工智能和5G被列为2022年及以后最重要的技术趋势
- 三星|谁说小米是组装厂?相继突破14项技术,未来还要投1000亿搞研发
- QQ音乐|拒绝Type-c接口共用,想要3.5mm耳机孔,这三款手机很不错!
- ColorOS|不要小看负一屏!体验ColorOS 12之后,感觉对负一屏上瘾了!
- 雷蛇|今年核心主线科技股的三个主要方向
- CPU|未来将布局VR生态体系 红魔7迎来官宣 将于2月发布号称地表最强