
文章图片
【微信|透过全球首个知识增强千亿大模型,看到中国AI差异化发展之路】
文章图片
文章图片

几年来 , 预训练大模型逐渐从一个AI领域内的技术语言 , 变成了强势出圈的产业热点与社会关注话题 。 但如果大家关注这一话题 , 会很容易注意到越来越多的声音开始反思大模型的发展之路 。 比如 , 大模型是不是应该一味追求庞大的训练参数?在发展路径上我们是不是只能严格对标GPT-3等国际著名大模型产品?
当中国科技企业与研究机构纷纷投入大模型竞争时 , 是不是有可能探索出一条属于自己的道路?
在科技自立的需求愈发严峻与明确时 , 透过大模型竞赛 , 我们可以看到更多关于AI的产业启示与战略思考 。
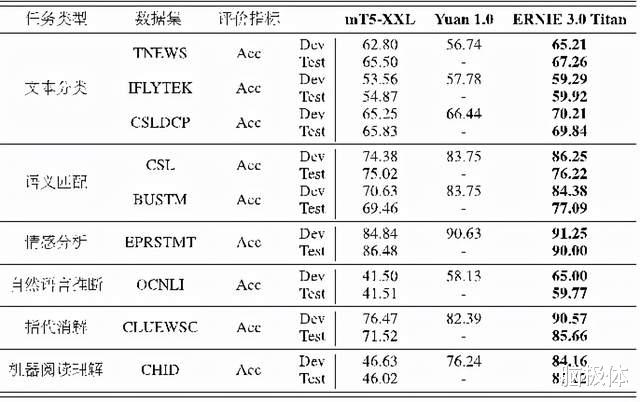
12月8日 , 鹏城实验室与百度联合召开发布会 , 正式发布双方共同研发的全球首个知识增强千亿大模型——鹏城-百度·文心 。 这一大模型参数规模达到2600亿 , 并且在全球60多项NLP任务中取得了最佳效果 。 同时 , 百度产业级知识增强大模型“文心”家族也首次亮相 。
早在2019年 , 百度就开始布局文心预训练模型 , 如今它也率先走向了差异化拐点 。 当大众对知识增强这一概念的熟稔远不如大模型本身时 , 百度文心选择了这条听上去陌生 , 但却至关重要的产业新径 。
大模型为什么重要?为什么我们应该在大模型上探索出新的方向?透过百度文心大模型 , 我们看到的是科技自立的远方 , 看到的是中国AI的飞翔之地 。
大模型不是军备竞赛 , 而是教育竞赛
首先来看大模型本身的行业意义与发展背景 。
如今 , 似乎每家AI企业和研究机构都在做大模型 。 这种火热局面经常被称为“大模型的军备竞赛” 。 但如果我们要理解的是 , 大模型本身是一种产业基础设施和辅助工具 , 并不是企业与机构的“不传之秘” 。
AI产业发展大模型 , 就像是国家发展教育事业 , 本身是为了培养更多人才和创新能力 , 增强整个社会的能动性 。
通过海量数据的预训练集成 , 大模型可以有效降低个体企业与具体行业的AI应用门槛 , 解决数据标注与行业差异化适配的问题 。 大模型就像一间间学校 , 培养了具有通识能力与高素质的人才 , 从而避免了企业需要从小学知识开始重新培养人才 。
这也就将引出一个关键问题:既然大模型是一种“教育系统” , 那么教育就应该贴合社会的实际需求 。 学校肯定不是以用掉了多少书本来评价质量 , 就像大模型不能仅以训练参数定优劣 , 更重要的是教育方法是不是与社会适配 , 能否培育出具有强大能力的人才 。
从这个维度上思考 , 中国AI产业要一直跟随GPT-3等大模型的脚步 , 一味在训练参数上标榜自身吗?
中国的产业底座、应用需求、技术领导力 , 是否有可能培育出自己的差异化大模型之路?
此次百度发布的鹏城-百度·文心 , 以及亮相的百度文心大模型 , 或许就是答案的方向 。
跳出藩篱:知识增强大模型的差异化之路
2019年3月 , 在全球大模型的刚刚开始起步的时候 , 百度就发布了ERNIE 1.0版本 , 提出了知识增强的语义表示模型 。 2019年7月 , ERNIE 2.0 则构建了持续学习语义理解框架 , 在中英文 16 个任务上取得了业界最佳效果 。
相关经验推荐














- 微信|微信更新内测版,OPPO Find N支持平板模式登陆
- 天玑9000|全球首款天玑9000手机,OPPO Find X5终于来了!
- 苹果|三星小米甘拜下风!苹果正式成为全球第一:iPhone 13迎来大降价
- 小米科技|实力媲美小米、TCL,国产彩电龙头走向全球,从海外赚回731亿
- 芯片|一家日本味精公司,却卡住了全球芯片企业的脖子,真的假的?
- 微软|微软改写全球科技行业格局,游戏成主角
- 家居|透过《2021年舒适家电白皮书》看家电企业如何向上生长?
- 微信|微信8.0.17更新!解锁超多功能!
- iPhone|全球手机市场排名重新洗牌:小米第三、三星第二、第一预料之中
- 小米科技|中国科技公司“新突破”,首发超宽频马达,常年稳居全球第一!